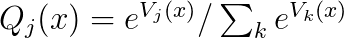Softmax


 doesn't need to be the base and a more general form for the function is:
doesn't need to be the base and a more general form for the function is: where
where  can be altered to effectively change the base. It can be understood from this format how softmax approximates argmax.
can be altered to effectively change the base. It can be understood from this format how softmax approximates argmax. 
 . Thus, the softmax activation function is said to generalize the sigmoid activation function to higher dimensions.
. Thus, the softmax activation function is said to generalize the sigmoid activation function to higher dimensions.
Wikipedia has good coverage of the motivation of the softmax function.
The name "softmax" originates in contrast to the argmax function (considered a hard-max) which extracts the index of the element having the greatest value.
The argmax function with one-hot encoding:
Compared to the softmax function:
doesn't need to be the base and a more general form for the function is: where can be altered to effectively change the base. It can be understood from this format how softmax approximates argmax. Benefits of softmax over argmax include:
* softmax is differentiable
* softmax is continuous
* softmax is monotonic
* softmax is positive for all inputs
Properties of softmax:
* invariant under translation. 
* not invariant under scaling.
The sigmoid function is a special case of the softmax function. The sigmoid function is a softmax of 1D input in 2D space where one variable is kept as 0 (e.g. input is points along the x-axis in the (x,y) plane):
. Thus, the softmax activation function is said to generalize the sigmoid activation function to higher dimensions.History
From Wikipedia:
In machine learning, the term "softmax" is credited to John S. Bridle in two 1989 conference papers, Bridle (1990a):[8] and Bridle (1990b):[3]
We are concerned with feed-forward non-linear networks (multi-layer perceptrons, or MLPs) with multiple outputs. We wish to treat the outputs of the network as probabilities of alternatives (e.g. pattern classes), conditioned on the inputs. We look for appropriate output non-linearities and for appropriate criteria for adaptation of the parameters of the network (e.g. weights). We explain two modifications: probability scoring, which is an alternative to squared error minimisation, and a normalised exponential (softmax) multi-input generalisation of the logistic non-linearity.[9]For any input, the outputs must all be positive and they must sum to unity. ...Given a set of unconstrained values,, we can ensure both conditions by using a Normalised Exponential transformation:
This transformation can be considered a multi-input generalisation of the logistic, operating on the whole output layer. It preserves the rank order of its input values, and is a differentiable generalisation of the ‘winner-take-all’ operation of picking the maximum value. For this reason we like to refer to it as softmax.